Magic Square Tic Tac Toe
Introduction
Adding to my expanding collection of Explorable Explanations (EEs), I’ve been interested in isomorphs of various board games. For example, the game Snakes and Ladders / Chutes and Ladders (a game with zero player agency originally intended to teach Hindu children the concepts of karma and destiny), can be played with just a six-sided dice and some rules:
- Each player takes turns rolling the dice. Starting at zero, they add each role to their score.
- If a player’s score is any of the following, change it according to this chart:
Value New Value Value New Value 1 38 48 26 4 14 49 11 9 31 56 53 21 42 63 19 28 84 64 60 36 44 92 73 51 67 95 76 71 91 98 78 80 100 - The first player to reach 100 wins.
Similarly, for this EE, I wanted to construct an example of tic-tac-toe as an isomorph (previously covered here). For which the rules are quite simple:
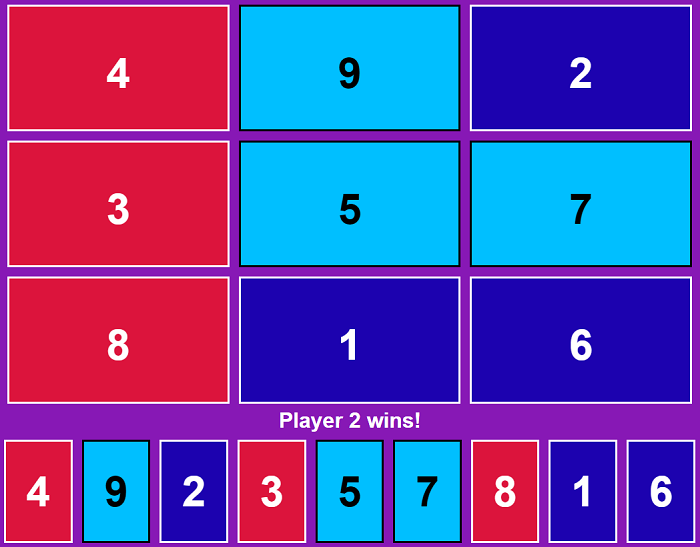
- Players take turns choosing a numbers between one through nine. Each number may only be claimed by one player.
- The first player with three numbers adding up to 15 wins.
The relationship between this game and tic-tac-toe can be expressed visually with a magic square like so:
| 4 | 3 | 8 |
| 9 | 5 | 1 |
| 2 | 7 | 6 |
Adapting a Tic-Tac-Toe AI
Tic-tac-toe is a solved game, one for which the outcome is known if both players play perfectly. For tic-tac-toe, the game will always result in a tie. Something even the characters in the 1980s film War Games noted as a reason the game’s popularity wanes after elementary school.
However, with only 26,830 possible games, it’s a great game to practice coding and learn some basic algorithms used in gaming. In fact, the game has even been rendered in the finite-state machine form of a branching-path book titled Tic Tac Tome by ThinkGeek industrial designer Willy Yongers. Within its 1,400 pages, the gamebook will always win or tie against the reader.
This relative simplicity means you can use innovations like the minimax algorithm, which explores every possible game state to find the move with the best outcome. Lucky for me, living in the age of “programming as putting together code like Legos,” I quickly found a great minimax algorithm tutorial by Vivek Panyam. His algorithm worked with tic-tac-toe board states, which I modified to work with sets of numbers.
The algorithm works by calling itself recursively and, when a branch ends in a winner or tie, returns a positive or negative score based on who won and when. For example, here’s a look at two branches and six steps of the 582 nodes for move number four:
|
||||||||||||||||||||
| 1 |
|
|
||||||||||||||||||
| 2 |
Result: (depth – 10) = -8 |
|
||||||||||||||||||
| 3 |
|
|||||||||||||||||||
| 4 |
Result: (depth – 10) = -6 |
|||||||||||||||||||
Because player one is one move away from winning, the left branch returns a -8 score, while the right returns a -6 for an opponent win two moves from now. The algorithm takes the -6 move as the better score. Similarly, if the algorithm were player one, then the scores would be 8 and 6 respectively and it would go with the 8 move for the win.
Because my adaptation was so different, working with sets of numbers instead of a board, there was lots of opportunity for making mistakes and therefore lots of opportunity for learning and discovery.
The AI Outplays Me
Keep in mind here I’m using the term “AI” very loosely. The AI Effect is the phenomenon of AI meaning “anything that has not been done yet.” Chess program? That was AI until people understood how the programs worked. Then it stopped being intelligent. Amazon Alexa and Google Assistant were AIs until users conversed with them enough to understand their boundaries. Autonomous cars? Once we solve that problem and people understand it, that won’t be considered intelligent either. So my use of “AI” is synonymous with “bot, “NPC”, “Algorithmic Intelligence,” or “fundamental attribution error.”
My first surprise debugging the game was that the AI beat me on turn two by claiming {8,7}. In its exploration of all the branches of possible moves, it found a win condition with two numbers rather than three. “How clever!” I thought. “Why didn’t I think of that?”
![[7,8] win](https://ideonexus.com/wp-content/uploads/2018/05/win.png)
[7,8] Win
Of course, the AI didn’t think of anything. The brute-force algorithm simply found that my WinCondition function would grant a win for any combination of numbers instead of enforcing the rule of triads for the win. It’s natural for human beings to falsely attribute motives and intentions to our chess programs or other bots. Our pattern-seeking brains find intelligence where there isn’t any.
So, I added a check, don’t run the win condition check until the user has made at least three selections. Again, the AI found the problem with this lazy fix. If any two numbers out of the three add up to 15, then a win was granted. So, once again, it grabbed {8,7,1}.
Stupid computers always doing exactly what you tell them to do.
I updated the win check to account for this, and in my debugging statements I was reminded of why I love coding so much. At one point I wanted to see how many steps the minimax algorithm was taking to see if it was in the right ballpark. It blew my mind to see the number of possibilities shrink dramatically with each move:
| Turn | P1 | P2 |
|---|---|---|
| 1 | 294,778 | 29,633 |
| 2 | 3,864 | 582 |
| 3 | 104 | 32 |
| 4 | 8 | 3 |
| 5 | 1 |
I mean, I knew this was the case, but the beauty of programming is mathematics as experimentation and discovery. Here I was discovering things; seeing how the code operates and getting a deep understanding of it.
Making the AI Defeatable
Since the purpose of my EE is to enhance students’ mathematical fluency–and possibly their n-back skills when playing away from the computer–having an unbeatable AI opponent is antithetical to having fun. So, my AI needed some levels for exercise and practice.
“Easy” level is easy, just take a random move. “Moderate” is trickier and raising the difficulty a little means revisiting the minimax function. I’ve seen many very difficult chess programs use this algorithm, even though chess has far too many possible game states to explore. Even calculating three moves ahead requires too much processing (without using alpha-beta pruning to kill losing branches). But thinking just a move or two ahead for obvious wins/loses seemed a good strategy to go.
Restricting the AI to thinking only two moves ahead worked well for setting up a simple challenge where the AI couldn’t anticipate a fork like so:

Fork Win
When adding another level of difficulty, thinking four moves ahead, I wasn’t sure if the game would be beatable. Rather than play game after game to find out, I enlisted the help of my AI friend and let the unbeatable AI face off against the hard one. The unbeatable AI won, but only when it was the first player. Making the hard AIs first move random created situations where an unbeatable player two AI could win, but only inconsistently.
Good enough.
Coding as a Deep Reading
There are cognitive benefits to coding exercises I wish every student could enjoy. The deep reading of code, spending hours engaged with a problem, the “flow” that comes with losing oneself in a complex task. Tic Tac Toe is a game and coding a tic tac toe AI is also a game. It has rules and boundaries that establish a magic circle the coder or player can step into and out of.
As with board games, the rules are written into the code, which imbues function names and programming syntax with meaning in the game space. As with video games, the rules are enforced behind the code, so that the player must explore and experiment to find what and how things are possible. The code is a virtual world, but the problems solved manifest as real-world outputs in the applications it produces.
Further Reading
- Durango Bill’s Magic Squares – brief simple overview of 3×3 magic squares of varying values.
- How to build an AI that wins: the basics of minimax search – where I got started with my own minimax search. Good demo of a tic tac toe AI.
- diegocasmo/tic-tac-toe-minimax – after reading many examples of tic tac toe minimax functions, I found I really liked this one for the way it includes a depth scoring and more readable code.